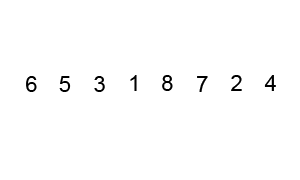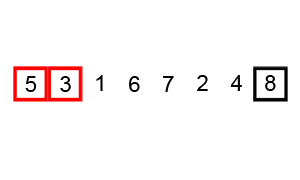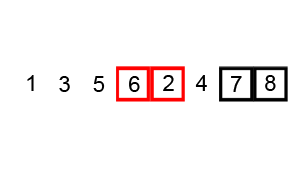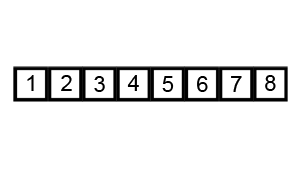body {
font-size: 100%;
}
.perspective {
background-image:
linear-gradient(
/*从上到下画渐变*/
/*起始点透明度为0.1,画到2.5%的高度*/
hsla(0,0%,0%,.1) 2.5%,
transparent 2.5%,
transparent 97.5%,
hsla(0,0%,0%,.1) 97.5%),
linear-gradient(90deg, hsla(0,0%,0%,.1) 2.5%, transparent 2.5%, transparent 97.5%, hsla(0,0%,0%,.1) 97.5%);
background-size: 3em 3em;
v-shadow 必需。垂直阴影的位置。允许负值
blur 可选。模糊距离
spread 可选。阴影的尺寸
color 可选。阴影的颜色
inset 可选。将外部阴影 (outset) 改为内部阴影。*/
box-shadow: 0 0 0 .25em hsla(0,0%,0%,.2);
height: 9em;
width: 9em;
position: absolute;
left: 50%;
top: 50%;
margin: -7.5em;
padding: 3em;
transform: perspective(500px) rotateX(45deg) rotateZ(45deg);
transform-style: preserve-3d;
transition: 1s;
}
.cube,
.cube:before,
.cube:after
{
width: 3em;
height: 3em;
float: left;
position: absolute;
box-shadow: inset 0 0 0 .25em hsla(0,0%,0%,.1);
content: '';
}
.cube
{
background: #f66;
position: relative;
transform: rotateZ(0deg)
translateZ(3em);
transform-style: preserve-3d;
transition: .25s;
}
.cube:after
{
background-color: #e55;
transform: rotateX(-90deg) translateY(3em);
语法:transform-origin: x-axis y-axis z-axis;
值 描述
x-axis 定义视图被置于 X 轴的何处。可能的值:
left
center
right
length
%
y-axis 定义视图被置于 Y 轴的何处。可能的值:
top
center
bottom
length
%
z-axis 定义视图被置于 Z 轴的何处。可能的值:
length
*/
transform-origin: 100% 100%;
}
.cube:before {
background-color: #d44;
transform: rotateY(90deg) translateX(3em);
transform-origin: 100% 0;
}
.cube:nth-child(even) {
background-color: #fc6;
}
.cube:nth-child(even):after {
background-color: #eb5;
}
.cube:nth-child(even):before {
background-color: #da4;
}
@keyframes wave {
50% {
transform: translateZ(4.5em);
}
}
.cube:nth-child(1) {
语法:animation: name duration timing-function delay iteration-count direction;
值 描述
animation-name 规定需要绑定到选择器的 keyframe 名称。。
animation-duration 规定完成动画所花费的时间,以秒或毫秒计。
animation-timing-function 规定动画的速度曲线。
animation-delay 规定在动画开始之前的延迟。
animation-iteration-count 规定动画应该播放的次数。
animation-direction 规定是否应该轮流反向播放动画。
*/
animation: wave 2s .1s ease-in-out infinite;
}
.cube:nth-child(2) {
animation: wave 2s .2s ease-in-out infinite;
}
.cube:nth-child(3) {
animation: wave 2s .3s ease-in-out infinite;
}
.cube:nth-child(4) {
animation: wave 2s .4s ease-in-out infinite;
}
.cube:nth-child(5) {
animation: wave 2s .5s ease-in-out infinite;
}
.cube:nth-child(6) {
animation: wave 2s .6s ease-in-out infinite;
}
.cube:nth-child(7) {
animation: wave 2s .7s ease-in-out infinite;
}
.cube:nth-child(8) {
animation: wave 2s .8s ease-in-out infinite;
}
.cube:nth-child(9) {
animation: wave 2s .9s ease-in-out infinite;
}
input {
display: none;
}
label {
background: #ddd;
cursor: pointer;
display: block;
font-family: sans-serif;
width: 4.5em;
line-height: 3em;
text-align: center;
position: absolute;
right: .5em;
top: 4em;
transition: .25s;
}
label[for="left"] {
right: 10.5em;
}
label[for="reset"] {
right: 5.5em;
}
label[for="up"] {
right: 5.5em;
top: .5em;
}
label[for="down"] {
right: 5.5em;
top: 7.5em;
}
label:hover {
background-color: #bbb;
}
input:checked + label {
background-color: #666;
color: #fff;
}
#left:checked ~ .perspective {
transform: perspective(500px) rotateX(45deg) rotateZ(75deg);
}
#right:checked ~ .perspective {
transform: perspective(500px) rotateX(45deg) rotateZ(15deg);
}
#up:checked ~ .perspective {
transform: perspective(500px) rotateX(75deg) rotateZ(45deg);
}
#down:checked ~ .perspective {
transform: perspective(500px) rotateX(15deg) rotateZ(45deg);
}